

A More Complex Financial Modeling Landscape: The Need for Explainability
An introduction to a blog series on Explainable Artificial Intelligence (XAI) in finance, aimed at readers interested in the intersection of artificial intelligence and financial decision-making.

The Rise of Complex AI Models in Finance
“Financial modeling is increasingly complementing traditional, assumption-driven frameworks with more flexible machine learning approaches that can learn complex patterns directly from data.”
Artificial intelligence (AI) is often perceived as a recent technological breakthrough, but its origins date back several decades. The foundations of AI were established in the mid-20th century, when early researchers began developing algorithms capable of learning patterns from data and making automated decisions1. Methods such as linear models, decision trees, and early neural networks have been studied and applied for many years2. In domains such as insurance, these models have long supported tasks like risk assessment, premium pricing, and claims analysis. Importantly, many of these earlier models were relatively transparent. Actuaries could point to clearly defined variables (inputs to the model), such as age, vehicle type, claims history, etc., and explain how each factor contributed to the final premium. For example, linear models provide explicit slope coefficients indicating the influence of each variable, as seen below.
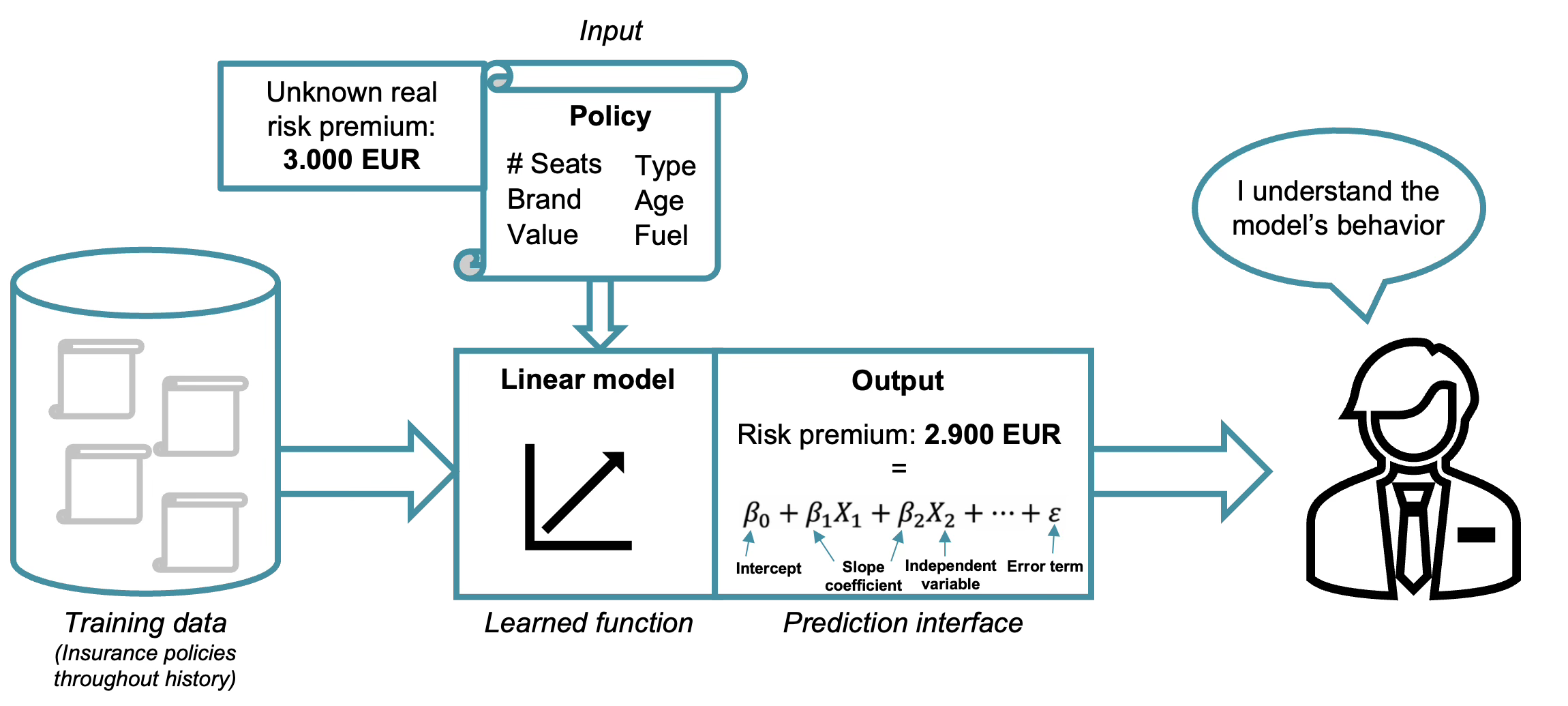
The logic, while technical, was traceable. The model’s structure allowed practitioners to trace how input variables influenced the prediction of “Risk premium: 2,900 EUR”, making it easier to explain decisions to stakeholders and regulators.
What has changed in recent years is not the existence of AI itself, but the scale and complexity of the models being deployed. Advances in computational power, the availability of large financial datasets, and improvements in machine learning algorithms have enabled the potential use of far more sophisticated models than was previously feasible3. As a result, complex techniques such as deep neural networks, ensemble models, and reinforcement learning systems are increasingly being applied to financial problems4.
Today, complex AI models are used more and more in financial decision-making. From stock price prediction and premium pricing to fraud detection and risk forecasting, machine learning models are increasingly responsible for final outcomes in high-stakes domains such as finance5. What once required simplified models and strong statistical assumptions can now be approached with architectures capable of capturing complex, non-linear, and high-dimensional relationships. From a purely technical perspective, this progress is remarkable. Financial modeling is increasingly complementing traditional, assumption-driven frameworks with more flexible machine learning approaches that can learn complex patterns directly from data.
The Problem of Complex AI Models
“The more powerful the models become, the less transparent they often are.”
At first glance, the added benefits of complex AI models look great. We are finally moving into an era where we have the computational capacity to uncover hidden patterns in vast amounts of financial data.
But here is the tension.
The more powerful the models become, the less transparent they often are. We call this a black-box model, where the internal logic of the model becomes opaque and difficult to interpret. In many modern machine learning systems, especially deep learning models, the relationship between inputs and outputs is encoded in thousands or millions of parameters, making it nearly impossible for humans to directly understand how a particular prediction was produced.
This creates a fundamental trade-off between predictive performance and interpretability6. Increasing model complexity can improve performance. However, this same complexity makes it harder to explain, validate, and scrutinize the model’s decisions. In other words, the characteristics that enable these models to achieve strong predictive accuracy often come at the cost of transparency.
In finance, this lack of transparency is not just an inconvenience; it is a structural risk. When a black-box model predicts a market downturn, reallocates capital, or flags a transaction as fraudulent, stakeholders need to understand why. Not just because they are curious, but because:
Traders need to assess reliability.
Regulators demand accountability.
Risk managers require validation.
Institutions must justify decisions to clients and boards.
An illustrative example is the calculation of a risk premium in an insurance context, similar to the example discussed previously. Historically, such pricing decisions were based on relatively transparent statistical models.
Today, imagine a modern AI-driven setup where an insurance company trains a deep learning model on thousands (or even millions) of historical policies. These inputs pass through a complex neural network trained on historical data. The output: “Risk premium: 2,950 EUR”. The prediction is more accurate than the example of the linear model showed earlier.
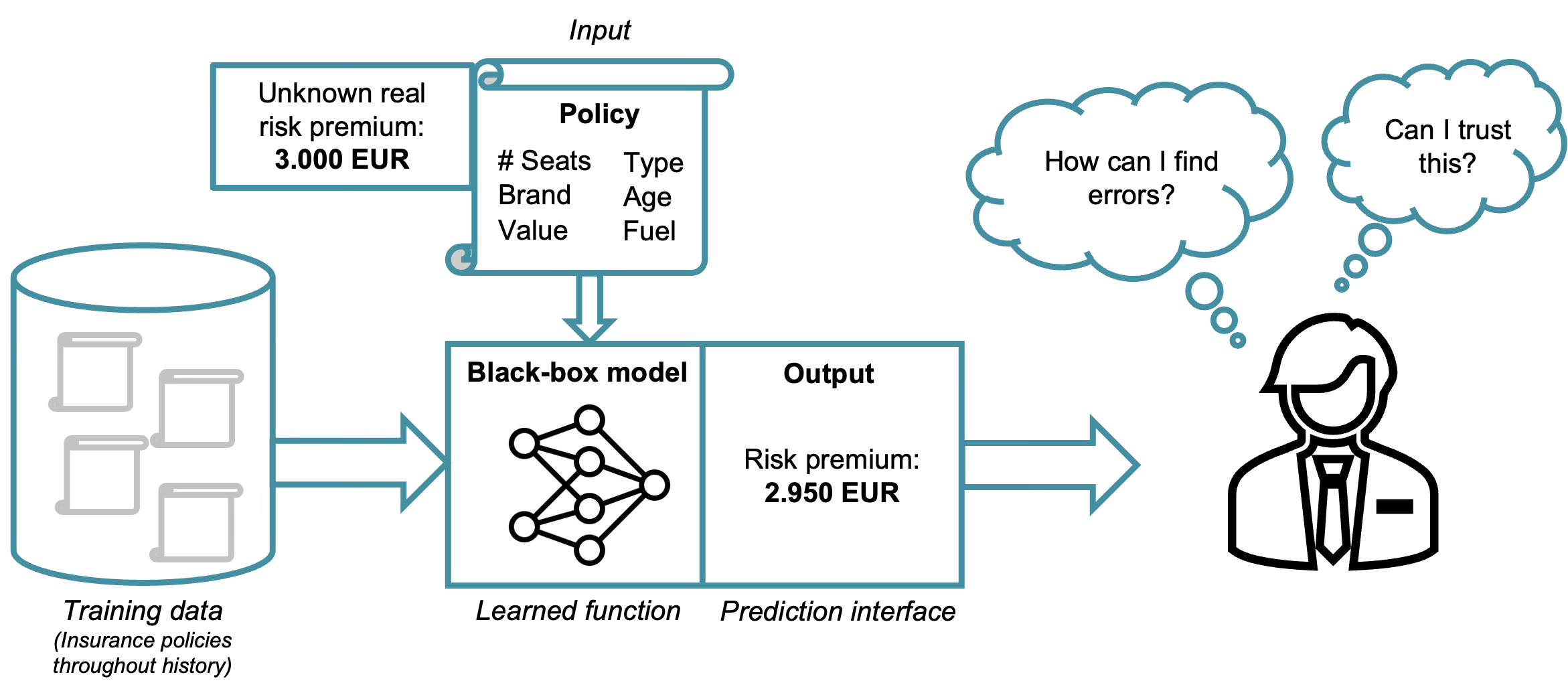
The model may capture non-linear interactions that traditional actuarial models cannot. For example, the effect of age on insurance risk may depend strongly on driving experience: a 22-year-old with five years of driving experience may have significantly lower risk than a 22-year-old with only a few months of experience. A linear model can capture such effects, but only if the interaction is explicitly specified. The difficulty is that the modeler must know and manually include the correct interaction terms, whereas complex AI models can often discover them automatically.
Now, consider the perspective of the decision-maker, or the regulator, looking at the previous shown output created by the black-box model. Questions arise such as:
How can I find errors in the created AI model to improve it?
Can I trust the prediction outcomes provided to me by the AI model?
The internal transformation from input variables to the final premium is no longer transparent. The “learned function” exists inside a high-dimensional parameter space. Even if the model performs well on validation data, understanding why it produced this specific premium for this specific policyholder is not straightforward anymore.
(Potential) Solution: Explainable Artificial Intelligence
And here’s where Explainable AI (XAI) enters the story. XAI is a method that allows human users to comprehend and trust the results and output created by machine learning algorithms. XAI is used to describe an AI model, its expected impact and potential biases.
Several methods have been proposed to provide such explanations. For example, Local Interpretable Model-agnostic Explanations (LIME)7 approximates complex models locally with simpler interpretable models to explain individual predictions. SHapley Additive exPlanations (SHAP)8 use concepts from cooperative game theory to attribute a model’s prediction to its input features in a consistent way. Another approach is Integrated Gradients9, which explains predictions of deep neural networks by attributing the output to the input features based on gradient information.
Together, these and related methods aim to bridge the gap between highly accurate yet opaque models and the need for transparency in decision-making systems. How these XAI methods are contributing to explainability is visualized below in the same insurance example.
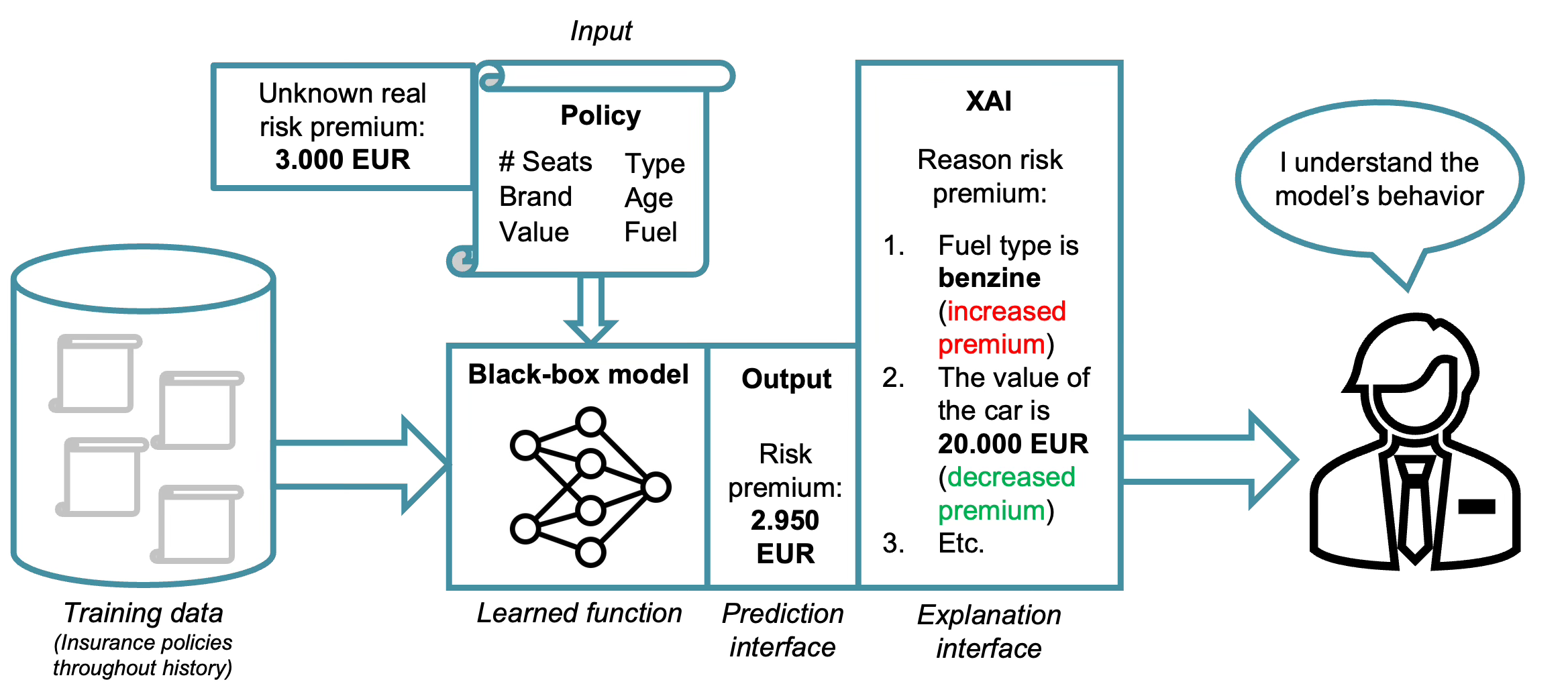
XAI acts now as an additional layer between the model’s output and the human decision-maker. Instead of simply presenting: “Risk premium: 2,950 EUR”, the system now provides a structured breakdown how this decision was formed:
Fuel type (benzine) → increased premium.
Vehicle value (20,000 EUR) → decreased premium.
Other contributing factors → etc.
At first glance, this additional layer appears to address the transparency problem. The black-box model itself remains complex, but the explanation layer translates the model’s behavior or predictions into components that are more interpretable for human users, for example by highlighting the input features (such as the fuel type) that contributed most strongly to a particular prediction.
The decision-maker no longer sees only a number: they see contributing factors. The output becomes contextualized. The premium becomes narratively structured. And this helps in several important ways:
Error detection. If the explanation highlights an irrelevant feature (e.g., fuel type dominating when it should not), practitioners can investigate.
Trust. When explanations align with domain knowledge, confidence in the model increases.
Bias detection. If sensitive or unintended attributes influence the output, XAI can reveal that.
Regulatory justification. Institutions can document and communicate why a pricing decision was made.
In short, this additional XAI layer transforms a raw prediction into an explained decision.
Or at least, it appears so.
The Road Ahead
XAI is often presented as the solution to the transparency problem of modern machine learning. However, an important question remains: Are we truly explaining these models, or are we only producing explanations that appear convincing?
Many popular XAI techniques rely on assumptions that may not hold in financial settings, particularly when dealing with noisy, non-stationary data. In such cases, explanations may become unstable, misleading, or overly sensitive to small changes in the input data. If explanations themselves are unreliable, they may create a false sense of transparency rather than genuine understanding.
This tension motivates the core research behind my research project. Instead of asking only how we can generate explanations, we must also ask when these explanations are trustworthy, for whom they are useful, and under which conditions they remain reliable in financial applications.
In the upcoming posts, we will explore questions such as:
Why do certain XAI methods dominate financial applications, and which ones are actually used in practice?
How do financial time series violate key assumptions behind many widely used XAI techniques?
What do regulators, risk managers, traders, and data scientists truly require from model explanations?
And most importantly: how can we develop explainability approaches that remain robust in real financial environments?
Stay tuned.
About the Project
Our work within Work Package 3 of the MSCA Digital Finance Doctoral Network is an exploration into the next generation of financial AI. We are investigating how to move beyond black-box solutions toward models that are inherently more transparent and trust-oriented. By developing and testing methodologies, such as non-perturbation-based XAI, we aim to describe how well current and novel tools meet the diverse needs of the financial value chain.
As we continue to validate these approaches against industry baselines and explore their impact on algorithmic fairness, we invite a dialogue with the following stakeholders:
Industry Practitioners: Are you interested in the practical trade-offs between predictive performance and explainability, or looking to test how audience-dependent explanations function in real-world use cases?
Regulators: Would you like to discuss technical benchmarks for “meaningful transparency” and how to evaluate AI systems against modern European requirements for trust and unbiasedness?
Researchers: Are you working on novel XAI methods, time-series dependencies, or causal inference, and looking to collaborate on advancing the state of the art in high-risk financial applications?
We believe that building human-centric AI requires an interdisciplinary effort. We invite you to reach out to discuss our findings, share your perspectives, or explore potential collaboration in this evolving field.
Contact Information
Connect with the author:
Follow my research updates: XAI in Financial Time Series
Connect with our project:
Follow our research updates: MSCA Digital Finance Doctoral Network | LinkedIn
Direct Inquiry: branka.hadjimisheva@bfh.ch
Acknowledgments

McCarthy, J., Minsky, M., Rochester, N., & Shannon, C. (1956). A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
Ozbayoglu, A. M., Gudelek, M. U., & Sezer, O. B. (2020). Deep learning for financial applications: A survey. Applied Soft Computing, 93, 106384.
Černevičienė, J., Kabašinskas, A. (2024). Explainable artificial intelligence (XAI) in finance: a systematic literature review. Artificial Intelligence Review 57, 216.
Barredo Arrieta, A., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., Chatila, R., & Herrera, F. (2020). Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion, 58, 82–115.
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
Lundberg, S. M., & Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. Advances in Neural Information Processing Systems (NeurIPS).
Sundararajan, M., Taly, A., & Yan, Q. (2017). Axiomatic Attribution for Deep Networks. Proceedings of the International Conference on Machine Learning (ICML).